
소란한 블로그
[TIL-210201] Ridge Regression 본문
1. Categorical data(범주형 자료)처리: One-hot encoding
Categorical data는 데이터에 우선순위가 있는 경우(nominal)와 순서가 없는 경우(ordinal)으로 나뉜다.
아래의 방법은 nominal를 처리하는 방법이다.
많은 머신러닝 모델들은 문자열을 처리하지 못하기 때문에 숫자형으로 바꾸어주어야 한다.단순히 1, 2, 3, 4와 같이 양적인 측정을 할 수 있는 숫자로 바꿔줄 경우 데이터에 순위가 생겨 분석에 차질이 생길 수 있다.따라서 nominal일 경우 각 항목마다 columns을 나누어서 1, 0, 0, 0 / 0, 0, 1, 0 이런 식으로 인코딩을 해주어야한다.이것이 바로 one-hot encoding이다.
- 방법1) pandas: get_dummies
get_dummies 함수는 pandas 패키지에서 지원하는 메소드이다.
categorical data가 어떤 feature인지 지정해주어야 한다는 단점이 있다.
Dum = pd.get_dummies(df['Regionname'])
- 방법2) Category_encoders: OneHotEncoder
OneHotEncoder는 category_encoders 패키지를 설치해야 사용할 수 있다.
!pip install --upgrade category_encoders알아서 categorical feature를 찾아서 one-hot encoding을 해주기 때문에 무척 편리하다.
from category_encoders import OneHotEncoder
# one-hot encoding
encoder = OneHotEncoder(use_cat_names = True)
encodedNewDf = encoder.fit_transform(new_df)
encodedNewDf.head()그리고 아래와 같이, 원래 columns name을 참조하여 알아서 깔끔하게 정해준다.

2. feature selection: SelectKBest
수 많은 feature 중에서 회귀모델에 적합한 feature를 선택하도록 해준다.
k 를 임의로 설정하여 몇개의 feature를 선택할지 정해준다.
from sklearn.feature_selection import f_regression, SelectKBest
selector = SelectKBest(score_func=f_regression, k=20)
# 학습 데이터- fit_transform
X_train_selected = selector.fit_transform(X_train, y_train))
# 테스트 데이터- transform
X_test_selected = selector.transform(X_test)
# 선택된 특성, 선택되지 않은 특성 출력
allNames = X_train.columns
selectedMask = selector.get_support()
selectedNames = allNames[selectedMask]
unselectedNames = allNames[~selectedMask]
print('Selected names: ', selectedNames)
print('Unselected names: ', unselectedNames)3. Ridge Regression
Ridge 회귀는 기존 다중회귀선을 훈련데이터에 덜 적합이 되도록 만들어 주어서 test를 할 때 저 정확한 예측을 하도록 만들어준다.
회귀식은 다음과 같다.

여기서 𝛌의 값을 조절해주면서 정규화의 강도를 조절해줄 수 있다.
𝛌가 0으로 갈수록 다른 회귀계수들이 회귀식에 끼치는 영향이 커지고, 𝛌가 커지면 커질수록 다른 회귀계수들은 0에 가까워지며 그에 따라서 다른 회귀계수들이 회귀식에 끼치는 영향이 작아진다.
𝛌가 너무 커지면 기준 모델과 다르지 않게 되므로 적당한 값을 넣어주어야 한다.
결국 𝛌는 회귀계수의 개수를 줄여주는 역할을 한다. 𝛌 값을 적절히 조절해주면서 영향을 크게 주는 회귀계수만 남도록 하고 영향이 적거나 outlier가 있는 feature는 0에 가깝도록 만드는 것이다. 즉, ridge regression을 통해 feature selection을 할 수 있는 것이다.
from sklearn.linear_model import RidgeCV
# alpha 값을 여러개 넣어보고, 어떤 것이 best score인지 확인
alphas = [0, 0.0001, 0.0009, 0.001, 0.01, 0.05]
ridge = RidgeCV(alphas = alphas, normalize = True, cv = 3) # cv=3: cross validation을 3 그룹으로 나누어 실행.
ridge.fit(X_train_selected, y_train) # 선택한 feature를 가지고 ridge regression 모델 만듦
print("alpha: ", ridge.alpha_)
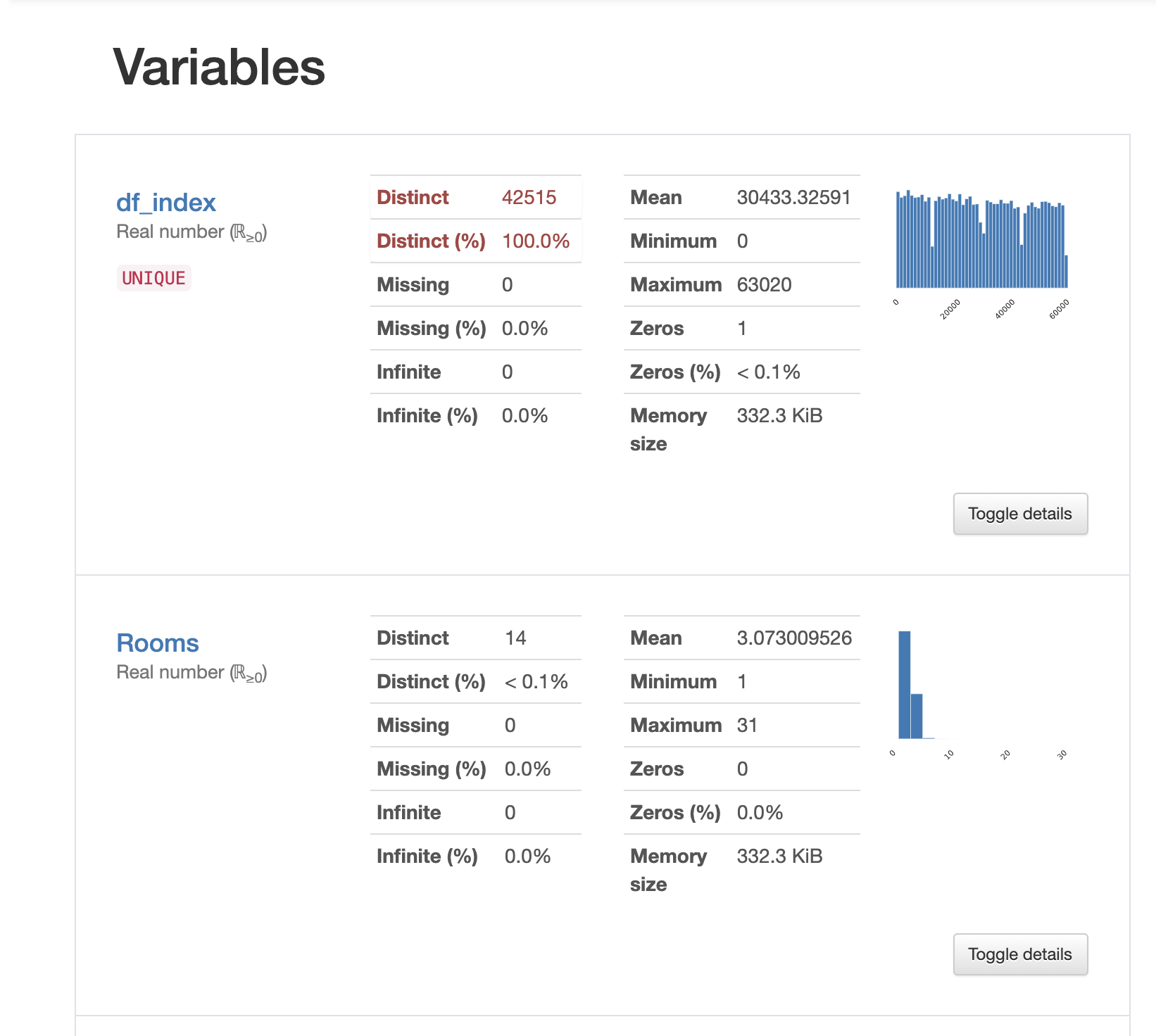
print("best score: ", ridge.best_score_)4. pandas_profiling: .profile_report()
pandas_profiling 패키지를 설치해서 .profile_report()를 사용할 수 있다.
!pip install -U pandas-profiling
이 메소드는 dataframe의 정보를 한눈에 깔끔하게 보여준다.
어떤 feature가 categorical data인지, 전체 데이터에서 결측치는 몇 퍼센트인지, correlations 등 시각화해서 보여준다.
이 자료를 참고하여 EDA를 하거나 outlier를 골라내어 좀 더 정확한 모델을 만들 수 있을 것이다.
pr = df.profile_report()
pr


5. 모델 성능 평가 지표
모델 성능 평가 지표 (회귀 모델, 분류 모델)
모델 성능 평가 모델을 만드는 이유는 일반화를 통해 미래(미실현) 예측을 추정하고자 하는 것이다. 그래서 우리는 train data로 학습시키고, 알고리즘을 계속해서 수정하고, 주어진 가설 공간에서
rk1993.tistory.com
* 이해가 부족한 내용
- 평가 지표를 통해 모델 성능 평가하기
- 다중공선성 문제?
- ridge regression 적용하기 복습
- train data set일 경우 => .fit_transform(X_train) // test data set일 경우 => .transform(X_test) ??
'Today I Learned' 카테고리의 다른 글
| [TIL-210406] 역전파(Backpropagation) (0) | 2021.04.06 |
|---|---|
| [TIL-210205] Random Forest (0) | 2021.02.05 |
| [TIL-210204] Decision Tree (0) | 2021.02.04 |
| [TIL-210202] Logistic Regression (0) | 2021.02.02 |


